|
MiniBachelor
|
|
MiniBachelor
|
Dies ist eine Mini-Version des Codes aus meiner Bachelorarbeit Entwurf und Implementierung verteilter Lösungsansätze für Capital Budgeting Probleme mit GLPK und Apache thrift. Dieser vereinfachte Code dient als Beispiel des Farmer-Worker-Modells und zeigt die Nutzung von Apache Thrift und glpk in C++. Dieser Code ist zu Ausbildungszwecken an der Hochschule Niederrhein (Krefeld, NRW) Ende 2015 für die Veranstaltung ,,Verteilte Systeme" bei Professor Rethmann erstellt worden.
Das Programm löst das ,,Projektselektierungs-Problem", in dem es aus einem großen Problem durch Vorbelegung - also ,,Vor-Selektion" - von Projekten viele kleine Probleme macht. Diese kleinen Probleme werden dann im Netzwerk an die Worker verteilt und dort mit glpk gelöst. Sollte das Lösen jedoch nicht in einer vorgegebenen Zeit fertig werden, wird das Problem erneut in kleinere Probleme durch Vorbelegung von Projekten unterteilt und erneut verteilt.
Beim Projektselektierungs-Problem wird eine binäre Kombination von Projekten gesucht, bei der ein Gesamtgewinn 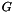 maximal ist. Binär heißt hier, man kann nicht ein Projekt fünf mal oder nur zu 80% (also 0,8 mal) wählen. Jedes von z.B. 250 Projekten garantiert am Ende eines Zeitraums von z.B. 30 Monaten einen Gewinn. Eine Wahl aller Projekte ist nicht möglich, da jedes Projekt in jedem Monat ganz unterschiedliche Kosten verursacht und für jeden Monat Budget-Grenzen eingehalten werden müssen. Damit es nicht zu kompliziert wird, fließt das übrig gebliebene Budget je Monat nicht in den Folgemonat oder in den Gesamtgewinn. Mathematisch hat man also eine Summe, die maximiert werden soll. Die Summanden sind der Profit
maximal ist. Binär heißt hier, man kann nicht ein Projekt fünf mal oder nur zu 80% (also 0,8 mal) wählen. Jedes von z.B. 250 Projekten garantiert am Ende eines Zeitraums von z.B. 30 Monaten einen Gewinn. Eine Wahl aller Projekte ist nicht möglich, da jedes Projekt in jedem Monat ganz unterschiedliche Kosten verursacht und für jeden Monat Budget-Grenzen eingehalten werden müssen. Damit es nicht zu kompliziert wird, fließt das übrig gebliebene Budget je Monat nicht in den Folgemonat oder in den Gesamtgewinn. Mathematisch hat man also eine Summe, die maximiert werden soll. Die Summanden sind der Profit 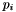 des Projekts
des Projekts 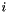 multipliziert mit dem Projekt
multipliziert mit dem Projekt 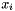 (1= Projekt gewählt, 0= nicht gewählt). Hinzu kommt zu jedem Monat
(1= Projekt gewählt, 0= nicht gewählt). Hinzu kommt zu jedem Monat 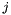 eine Ungleichung, die die Einhaltung des Budgets
eine Ungleichung, die die Einhaltung des Budgets 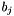 vorgibt. Bei einer Wahl von Projekten x muss für jeden Monat die Summe ihrer Kosten
vorgibt. Bei einer Wahl von Projekten x muss für jeden Monat die Summe ihrer Kosten 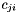 kleiner oder gleich dem Budget sein.
kleiner oder gleich dem Budget sein.
![\begin{eqnarray*} G = & \sum\limits_{i=1}^{250} p_{i} x_{i} & \mbox{ist zu maximieren} \\ b_{j} \geq & \sum\limits_{i=1}^{250} c_{ji} x_{i} & 1 \leq j \leq 30 \\[1em] & x_{i}\ \epsilon\ \{0,1\} \end{eqnarray*}](form_7.png)
Einiges aus meiner Bachelorarbeit ist der Einfachheit halber in diesem Code von mir weggelassen worden. Z.B. das sehr aufwändige Austauschen von Zwischenergebnissen und Abgleichen von besseren Lösungen während glpk rechnet (via callback-Funktion) ist von mir entfernt worden. Genauso fehlt eine Vorsortierung der Projekte nach der Summe ihrer Kosten pro Profit, so dass gewinnträchtige Projekte zuerst mit 1111.. vorbelegt werden. Diese Vereinfachungen sorgen dafür, dass die Verteilung nicht zwingend zu einer Beschleunigung der Berechnung führt.
Im Branch ,,speedup" habe ich mit jedem Commit folgende Features beigefügt:
Primäre ist der Code für Linux ausgelegt (Pfadangaben, Makefile, etc.) aber grundsätzlich wie in meiner Bachelorarbeit auch unter Windows und OS X lauffähig.
http://sourceforge.net/projects/minibachelor/
make clean um alles (excl. doc/ mit html-Dokumentation) zu löschenmake idl-compilemakemake docEs ist möglich, dass im Makefile der Pfad -L/usr/local/lib in dem die dynamischen Bibliotheken für thrift und glpk beim Linken gesucht werden, angepasst werden muss.
Da auf den Rechnern der Hochschule (stand Oktober 2015, Ubuntu 14.04.1) nur der thrift idl Compiler ist, muss man sich die header-Dateien von thrift besorgen und eine Bibliothek zum Linken, welche dazu passt. Für Boost (thrift benötigt Boost) ist nur die Bibliothek installiert. Die Header Dateien von Boost (es sind ein paar MB) brauchst du aber auch. Diese ganzen Dateien findest du hier:
http://sourceforge.net/projects/minibachelor/files/Thrift-und-Boost.zip/download
Die Bibliothek libthrift.a ist im Unterordner lib/ zu finden. Passe die Stelle im Makefile an:
LDOPTS = -pthread -lglpk -lthrift -L./lib
Die Header Dateien sind im Unterordner include2/ zu finden. Passe auch diese Stelle im Makefile an:
COPTS = -Wall -std=c++11 -I./include2
Mit make sollten nun alle Programme auf den Rechnern der Hochschule kompiliert werden können.
In diesem Kapitel werde ich Ihnen erklären, wie Sie unter Linux mit einem Bash-Script, der Secure-Shell (ssh) und dem Befehl nohup einen oder mehrere Befehle auf mehreren Rechnern automatisiert starten können.
Ein verteiltes System, welches z.B. mit zwei bis drei Servern aus kommt und sich die Benutzer selber einen Client zur Benutzung installieren, ist bei einen Messanger die Regel. Wenn Sie aber ein verteiltes System haben, bei dem Aufgaben von einem (oder zumindest wenigen) Clients auf vielen Servern erledigt werden müssen, dann müssen die Server von einem Client gestartet werden können.
crontab keine OptionSie können davon ausgehen, dass das GLI Labor beim Starten eines Rechners keine Serverdienste, die Sie programmiert haben, automatisch startet. Für ,,normale" Linux-User wäre dies mit einer ,,crontab" machbar. In dieser Tabelle kann zu bestimmten Zeiten ein Befehl von einem User ausgeführt werden, wie z.B. das Senden von Statusmeldungen einmal am Tag. Aber als Zeitpunkt kann auch ,,@reboot" eingetragen werden, so dass ein Befehl nach dem Starten ausgeführt wird. Aber: im GLI Labor können Sie das mit an Sicherheit grenzender Wahrscheinlichkeit nicht!
Angenommen Sie haben ein verteiltes System programmiert, was Arbeit an 32 Prozessoren verteilen kann (z.B. ein Filter für ein Bild, welches Sie in 32 Teile aufgeteilt haben oder Sie wollen 32 Bilder filtern), dann brauchen (oder wollen) Sie 32 Server laufen haben. Zum Glück stehen auf den Rechnern des GLI Labors je 4 Kerne (Quad-Core) zur Verfügung, so dass Sie mit 8 Rechnern auskommen. Sollte Ihr Server-Code allerdings mehrere aktive Threads nutzen oder Ihre Kommilitonen auf die selbe Idee kommen und gleichzeitig auf diesen Rechnern arbeiten, dann passt das mit den 4 Kernen nicht mehr.
Sehr unelegant ist es, wenn Sie sich in der graphischen Oberfläche 8x anmelden. Die Studenten, die an den Rechnern sitzen und noch vor sich hin tüfteln würden sich sehr gestört fühlen - das gilt auch, wenn Sie sich mit STRG+CTRL+F1 .. F6 auf einer der 6 nicht-graphischen Konsolen einloggen wollen. Deswegen: lassen Sie es! Wenn Sie z.B. im Raum B312 sind, dann sind die IP-Adressen von den Rechnern in den ersten 2 Reihen 192.168.12.1 bis 192.168.12.8 und Sie können mit dem Kommandozeilenbefehl ssh benutzername@IpAdresse - also mit Ihrem Benutzernamen und der IP-Adresse des Rechners - Zugang zum Rechner bekommen. Mit dem Befehl users bekommen Sie alle Benutzer aufgeführt, die zur Zeit an dem Rechner eingeloggt sind. Durch nfs ist Ihr home-Verzeichnis mit all Ihren Dateien auch an dem Rechner vorhanden. Sie könnten jetzt natürlich Ihren Server 4x mit unterschiedlichen Port-Adressen starten ...
./myServer 64001 & ./myServer 64002 & ./myServer 64003 & ./myServer 64004 &
... aber tun Sie das nicht! Wenn sie mit exit den Rechner wieder verlassen, dann versucht Linux diese Prozesse zu beenden.
Um das Beenden nach dem exit zu verhindern, gibt es den Befehl nohup. Wenn Sie Ihre Server so starten ...
nohup ./myServer 64001 & nohup ./myServer 64002 & nohup ./myServer 64003 & nohup ./myServer 64004 &
... laufen sie auch noch nach einem exit. Alle Ausgaben Ihres Servers werden dann in eine Datei nohup.out geschrieben, was bei einer Fehlersuche praktisch sein kann. Auch hier gibt es ein Problem: Stellen Sie sich vor, wenn später wegen nohub 32 Server über nfs gleichzeitig Meldungen in die selbe Datei schreiben wollen. Das geht im Prinzip nicht und jeder der Server müsste auf den anderen Warten, bis er seine Daten in die Datei geschrieben hat. Deswegen sollten Sie mit >> und 2>> die Standardausgabe und die Fehlerausgabe umleiten. Anstelle in eine Datei wie nohup.out schlage ich Ihnen das Nichts-Device /dev/null unter Linux vor:
nohup ./myServer 64001 >>/dev/null 2>>/dev/null & nohup ./myServer 64002 >>/dev/null 2>>/dev/null & nohup ./myServer 64003 >>/dev/null 2>>/dev/null & nohup ./myServer 64004 >>/dev/null 2>>/dev/null &
Mit exit können Sie den Rechner wieder verlassen und diese 4 Server-Prozesse werden weiter laufen. Wenn Sie sich ein paar Sekunden später erneut da einloggen, können Sie z.B. mit ps aux (was Sie aus BSY kennen) die Prozesse weiterhin sehen. Mit killall myServer können Sie auf einen Schlag allen myServer Prozessen ein Signal zur Terminierung senden und die Server wieder beenden.
Im nächsten Schritt sollten Sie sich einen ssh-key erstellen, damit Sie nicht bei jedem Zugang auf einen Rechner ein Passwort eingeben müssen. Weil auf diesen Key mit nfs zugegriffen wird, könnte es aber dazu kommen, dass Sie bei einem automatisiertem Einloggen trotzdem nach einen Passwort gefragt werden. Sollten Sie trotzdem (aber ein anderes, evtl. kürzeres Passwort) eingeben wollen, könnten Sie Ihren Key noch mit einem Passwort schützen. Sie werden zumindest bei dem kommenden Befehl optional nach einem Passwort gefragt:
ssh-keygen -t rsa -b 4096
Der Befehl legt in ~/.ssh/ eine Datei id_rsa und id_rsa.pub an. Es werden automatisch die Dateirechte so gesetzt, dass keine anderen User die Datei id_rsa einsehen können! Die Public-Version muss nun von Ihnen in die Datei ~/.ssh/authorized_keys eingefügt werden. Der SSH-Server jedes Rechners schaut in dieser Datei nach gültigen Keys.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Achtung! Ihnen muss klar sein: sobald Sie das getan haben, braucht man nur noch die id_rsa-Datei (Ihren privaten Schlüssel), um mit ssh einen Linux-Zugang mit Ihrem Login zu bekommen!
Durch die Möglichkeit sich ohne Passwort auf die Rechner ein zu loggen (sie müssen allerdings einmalig jeden Rechner zu den bekannten Hosts zufügen), können Sie Ihr Wissen über Bash-Skripte aus BSY anwenden. In meiner Bachelorarbeit hatte ich mir z.B. ein Skript gemacht, bei dem ich nur noch sh startServerB312.sh 1 2 3 4 5 6 7 8 eingeben musste, um auf den ersten 8 Rechnern je 4 Server zu starten. In einem Shell-Skript kann man in einer Schleife und der Variable $* auf alle beigefügten Kommandozeilen Parameter zugreifen. Mit einer zweiten Schleife lassen sich die Port-Adressen aus einem Array holen. Ssh ermöglicht außerdem das Ausführen eines Befehls, anstelle dem Öffnen einer ,,Shell" auf dem Rechner. Ein Bash-Skript, welches Sie genau mit der Angabe des letzten IP-Adressen Tupels benutzen können, könnte so aussehen:
Der Zusatz-Parameter -t in ssh ist notwendig, da sonst ssh zusammen mit & den nohup-Befehl nicht korrekt ausführt.
You are free to:
Share - copy and redistribute the material in any medium or format
Adapt - remix, transform, and build upon the material for any purpose, even commercially.
The licensor cannot revoke these freedoms as long as you follow the license terms.
Under the following terms:
Attribution - You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
No additional restrictions - You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
Notices:
You do not have to comply with the license for elements of the material in the public domain or where your use is permitted by an applicable exception or limitation.
No warranties are given. The license may not give you all of the permissions necessary for your intended use. For example, other rights such as publicity, privacy, or moral rights may limit how you use the material.
 1.8.10
1.8.10

